
Botany and Natural History specimen collections represent an unparalleled source of knowledge and research, and yet they are often inaccessible and underutilized due to their specialized nature. Descriptive metadata and identifications for these collections can be labor-intensive and time-consuming to generate, and often relies on the individual knowledge of subject matter specialists. While digitizing these collections allows the global scientific community ready access for study, Artificial Intelligence (AI) and Optical Character Recognition (OCR) can provide even deeper insights into these collections.
DT has partnered with Colgate University on a project funded by the Picker Interdisciplinary Science Institute to digitize the personal field notes and personal papers of renowned botanist, Alma Gracey Stokey. Not only did these papers include her articles, observations, and notes but also more than 10,000 detailed gametophyte illustrations from over 200 species of ferns. Prior to this project and initiative by the University, very little of this work had been shared publicly, contributing to the dark data that often surrounds these types of natural history and botany collections.
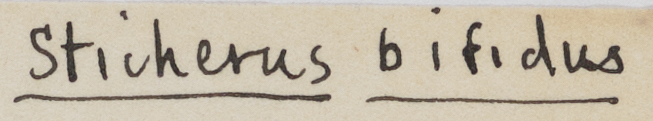 .
.
Drawing from Colgate University’s Alma Gracey Stokey botany papers collection with OCR-extracted handwritten text, identifying fern species sticherus bifidus with a 94.5% confidence percentage

Hand-drawn fern specimens and accompanying OCR-extracted label identifying species gleichenia bifida with a 100% confidence percentage.
Methodology
The high-quality, preservation-grade imaging of the DT Phase One IXG 100 MP camera was used to capture great detail within the hand-written notes and drawings. By creating these high-resolution archival digital assets, DT was then able to employ precision OCR to extract handwritten label information from the drawings and identify fern specimens within the collection.
DT began this process of identification through OCR with controlled vocabulary by preparing a referential lexicon or species list, which for the purposes of this project was the World Flora Online (WFO) World Flora Online Taxonomic Backbone. In order to prepare the images for the virtual workflow, DT applied proprietary image processing in order to help improve the OCR results as well as some proprietary text handling to cleanse the OCR and account for commonly-faced OCR issues, such as interjection of a superfluous space, the errant removal of a true space, confusion between similar looking handwritten letters such as 1, l (lower case L), and I (upper case i). These kinds of mistakes can often be automatically and confidently corrected when the context is common words. For example “When I go to the mall” will almost always have the “I” correctly read as a capital i. But in long uncommon words where more than one character is misdirected such ocr issues cannot be fixed automatically and must instead be corrected by techniques such as controlled vocabulary lookup as described in this article . In order to specifically identify the genus and species of the fern specimens as they were labeled in the drawings, DT parsed the OCR results, compared the words to those of the Species List, matched the species word components, and then matched the species to see if any combination of matched words matched a species, using a cousin of the Levenshtein Distance methodology. Once the matches were identified, the identifications were then input into a field within a Dublin Core metadata spreadsheet along with their confidence thresholds.
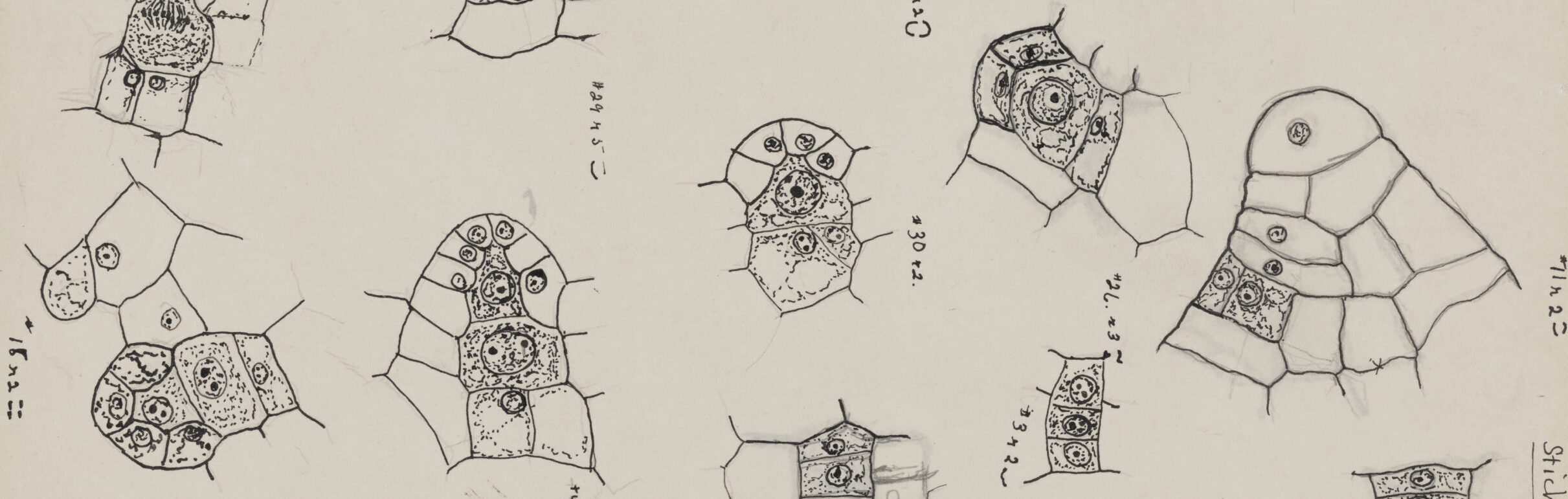
Hand-drawn fern specimens and labels from the Alma Gracey Stokey Collection at Colgate University
Conclusion
By implementing our in-house AI-powered OCR engine and increasing its precision using a controlled vocabulary lexicon, DT was able to refine the transcription process and increase its accuracy.
Although human interaction/oversight is still required, as with any automated process, by using our OCR with controlled vocabulary process, Colgate is currently using students rather than subject-matter experts to confirm the AI-automated identifications, saving them time and resources. These types of automations are incredibly valuable steps forward in the scientific identification process for specialized collections such as these and offer increasingly accurate alternatives to traditional metadata-gathering processes.
Contact us to learn more about how Digital Transitions uses the latest in digitization and AI technologies to help you make the most of your scientific collections.